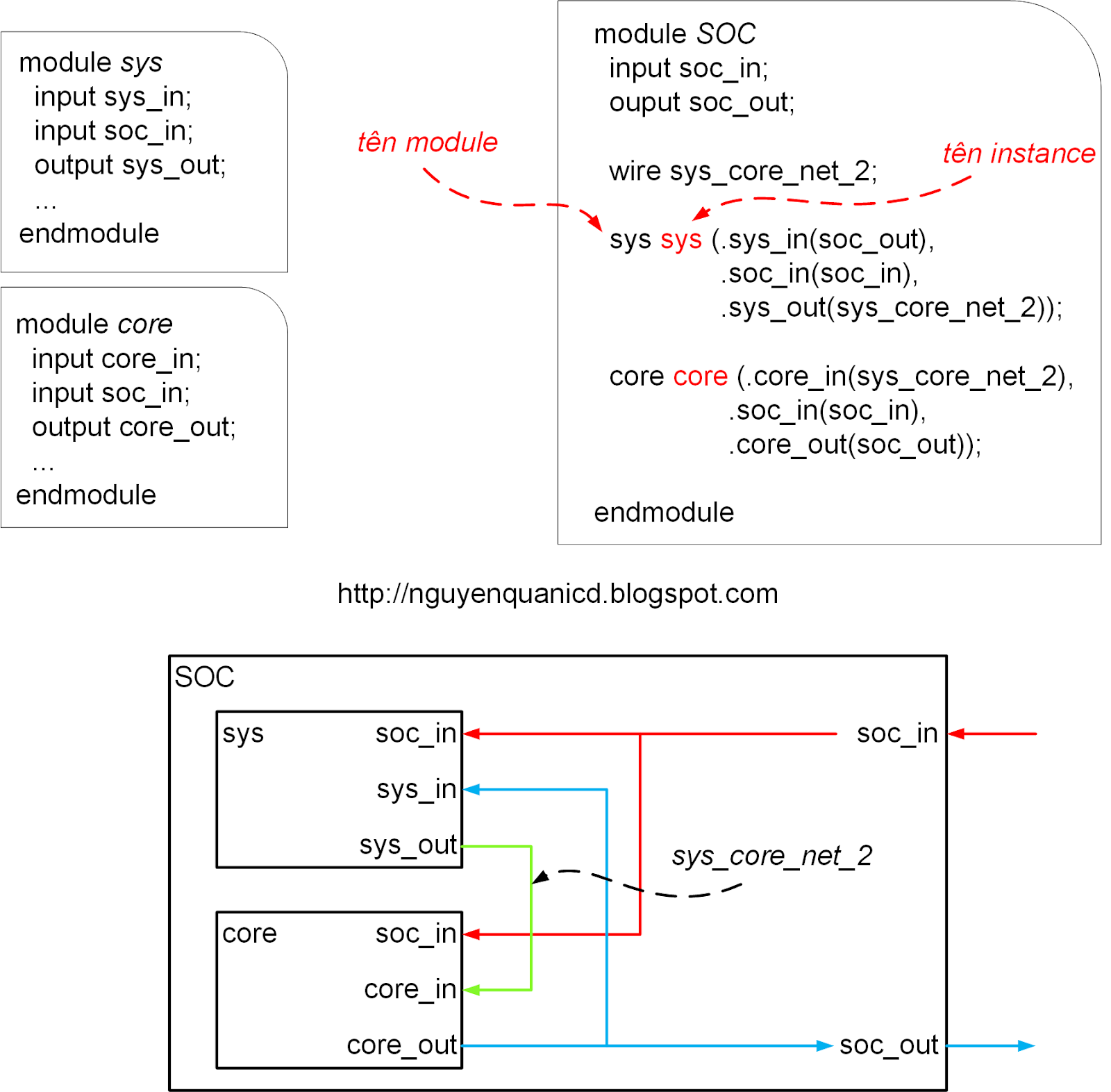
Vì nhiều bạn có email nhờ mình gợi ý một số đề tài để các bạn có thể lựa chọn làm đồ án nên mình tạo ra bài viết này với mục đích gợi ý một số đề tài và hướng nghiên cứu cho các bạn. Đối với mỗi đề tài, mình sẽ mô tả sơ qua nội dung, mục đích và lợi ích mà các bạn sẽ nhận được sau khi thực hiện xong. Bên cạnh đó, mình cũng nêu một số kinh nghiệm để bạn có thể chọn đề tài phù hợp.
1) Các yếu tố chính cần quan tâm
Chú ý, việc chọn đề tài phù hợp là tùy vào nhiều yếu tố nhưng mình sẽ trình bày trên quan điểm "đề tài là công việc đầu tiên và tiên quyết" chứ không phải là một môn học mà bạn chỉ tập trung cố gắng để qua môn. Khi xem "Đề tài là công việc đầu tiên và tiên quyết", bạn sẽ có thái độ chuyên nghiệp khi làm nó. Bạn sẽ cần có kế hoạch thực hiện cụ thể, mục tiêu? làm gì? bao lâu?, sẽ gặt hái được gì khi làm xong đề tài?, có giúp ích cho cơ hội nghề nghiệp không?. Khi có thái độ đúng, bạn sẽ hành động đúng và việc "qua môn" với kết quả tốt là hiển nhiên. Ngược lại, nếu bạn chỉ tập trung làm sao để qua môn thì bạn sẽ có xu hướng tìm các đề tài "dễ", những đề tài đã có người làm hoàn thiện, có source code sẵn, chỉ chỉnh sửa, đọc hiểu là được.
Lý do bạn gặp khó khăn khi không thể tự nghĩ ra đề tài nghiên cứu tìm hiểu là:
- Bạn chưa có đủ thời gian, kiến thức và kinh nghiệm để nghiên cứu, tìm hiểu, và đánh giá đề tài.
- Nhà trường ít cung cấp kiến thức về ngành nghề, cập nhật tình hình phát triển, hay truyền đạt các kinh nghiệm công việc thực tế hoặc có truyền đạt nhưng bạn không để ý.
- Năng lực hiện tại của bản thân
- Mục tiêu nghề nhiệp của bạn khi ra trường
- Xu thế tuyển dụng
- Học thuật và tính mới
Mục tiêu nghề nghiệp, sau năng lực, tác giả xếp yếu tố này ở vị trí thứ 2. Khả năng của bạn tốt nhưng không có mục tiêu nghề nghiệp đối với ngành "vi mạch số". Bạn mong muốn ra trường làm lĩnh vực khác hoặc đã định hướng rõ ràng sẽ làm lĩnh vực khác. Việc làm đề tài về "vi mạch số" chỉ để có thể nhanh chóng thực hiện, để "qua môn" với kết quả tốt thì bạn có thể lựa chọn đề tài mức "vừa phải.
Xu thế tuyển dụng, xu thế tuyển dụng sẽ ảnh hưởng lớn đến cơ hội nghề nghiệp sau khi ra trường là rộng hay hẹp. Một đề tài đem lại cho bạn kiến thức "hot" mà trị trường tuyển dụng đang săn đón tất nhiên sẽ ngon hơn. Đối với mục này, bạn cố gắng bỏ ra một chút thời gian tìm hiểu trên các trang tuyển dụng, trang web các công ty, các diễn đàn vi mạch điện tử để xem hiện họ đang cần gì? Trừ khi bạn có ý định đi nước ngoài, công việc rất nhiều và loại nào cũng có. Nếu bạn ở Việt Nam, bạn nên xem có những công ty nào, đang làm gì? Nếu bạn không có ý định làm thuê mà sẽ start-up với việc lập một công ty công nghệ thì tuyệt vời, những lời khuyên của tác giả sẽ là dư thừa và không đủ tầm với bạn vì bạn rất bản lĩnh.
Học thuật và tính mới, đây là yếu tố khó có thể bỏ qua khi bạn thực hiện một đề tài hay luận văn trong môi trường học đường vì nó giúp phân biệt đề tài bạn làm với các đề tài đã được làm trước đó. Khi bạn chọn làm đề tài, cố gắng tìm hiểu để trả lời được "đề tài này khác gì so với các đề tài tương tự?" hoặc "đề tài sẽ giúp giải quyết vấn đề gì, khó khăn gì?" trong lĩnh vực bạn nghiên cứu. Đối với một sinh viên, yêu cầu về cái mới hoàn toàn, chưa có ai làm trên thế giới, là vô cùng khó nhưng tối thiểu nên mới hơn so với những đề tài mà các bạn khác đã làm.
2) Đánh giá xu thế nghề nghiệp về lĩnh vực vi mạch
Quá trình điện tử hóa, tự động hóa diễn ra mạnh mẽ với công nghệ đổi mới liên tục và nhanh chóng. Tính cạnh tranh trong lĩnh vực này rất cao, nhiều công ty hàng đầu luôn cập nhật và áp dụng các tiêu chuẩn mới ngay cả khi nó chưa được công bố chính thức để dẫn đầu và định hướng thị trường. Việc một tiêu chuẩn được công bố, các công ty bắt đầu dựa trên đó là làm theo, điều này là bình thường và nhưng quá chậm. Các công ty hàng đầu sẽ tự đánh giá xu thế để làm trước các sản phẩm ngay khi tiêu chuẩn chưa ban hành.
Quá trình điện tử hóa, tự động hóa len lỏi vào tất cả các lĩnh vực, không chỉ mỗi công nghệ thông tin mà vào cả nông nghiệp, giao thông vận tải, quản lý, ... Ví dụ như:
- Nông nghiệp: điều khiển tưới tiêu, tự động đo đạc thông số môi trường và cảnh báo, ...
- Giao thông vận tải: giám sát hành trình phương tiện giao thông, giám sát lưu lượng xe trên đường, ...
- Quản lý: quản lý hàng hóa bằng chip điện tử, quản lý nhân sự bằng thẻ điện tử, ...
Với yêu cầu ngày càng cao, chức năng vi mạch (chip) phải tích hợp ngày càng nhiều làm cho các vi mạch SoC phát triển mạnh nên kiến thức về hệ thống SoC đã trở thành kiến thức được yêu cầu chung trong yêu cầu tuyển dụng.
Trong hệ thống SoC, các thành phần qua trong không thể thiếu (hầu như luôn tồn tại) là CPU, bus hệ thống, bộ nhớ (memory), module cấp clock, module cấp reset, module quản lý năng lượng (cấp nguồn), DMA nên nghiên cứu về các vấn đề này là lợi thế nghề nghiệp. Về đỉnh cao công nghệ, hiện nay, các ngoại vi liên quan đến giao thức tốc độ cao, băng thông lớn như Ethernet, USB, PCI, DRAM, Video/Audio (HDMI, H.264, H.265, ...) đang "hot" nên nghiên cứu về các vấn đề này sẽ cớ cơ hội nghề nghiệp cao.
Bên cạnh đó, trong flow thiết kế vi mạch số. Nhóm công việc liên quan đến Back-end (tổng hợp, synthesis, layout, ...) đang gia tăng ở Việt Nam và hiện là nhu cầu khá cao trên thế giới vì để có được kinh nghiệm trong phân khúc này không hề đơn giản. Nguyên nhân chính là nó phụ thuộc nhiều vào số thời gian làm việc, tiếp xúc trực tiếp với các phần mềm, thư viện chuyên dụng, có bản quyền để tạo ra các kết quả chính xác. Trong khi phần mềm cho front-end có thể dễ dàng tìm kiếm, cài đặt thì phần mềm dành cho back-end rất khó tìm free và đầy đủ để nghiên cứu và tìm hiểu.
3) Danh sách đề tài, luận văn
Bên cạnh đó, trong flow thiết kế vi mạch số. Nhóm công việc liên quan đến Back-end (tổng hợp, synthesis, layout, ...) đang gia tăng ở Việt Nam và hiện là nhu cầu khá cao trên thế giới vì để có được kinh nghiệm trong phân khúc này không hề đơn giản. Nguyên nhân chính là nó phụ thuộc nhiều vào số thời gian làm việc, tiếp xúc trực tiếp với các phần mềm, thư viện chuyên dụng, có bản quyền để tạo ra các kết quả chính xác. Trong khi phần mềm cho front-end có thể dễ dàng tìm kiếm, cài đặt thì phần mềm dành cho back-end rất khó tìm free và đầy đủ để nghiên cứu và tìm hiểu.
 |
| Hình 1: Vị trí nghề nghiệp trong lĩnh vực vi mạch số |
Danh sách đề tài luận văn mà các bạn có thể tham khảo thực hiện (chú ý, danh sách này sẽ được cập nhật liên tục khi tác giả có ý tưởng mới):
| TT | Tên | Nội dung |
| 1 | Thiết kế CPU với kiến trúc tập lệnh mở RISC-V | RISC-V đọc là "risk-five" là một tập lệnh mở và miễn phí, hiện nay cộng đồng hỗ trợ và phát triển RISC-V rất đông và đã có một số công ty start-up phát triển sản phẩm dựa trên kiến trúc tập lệnh này (https://riscv.org/). Nếu bạn chọn đề tài thiết kế CPU, đây là một gợi ý. Ưu điểm: mới hơn so với các đề tài hiện có vì các đề tài trước đây chủ yếu làm theo kiến trúc tập lệnh ARM, PIC. Bạn sẽ có kiến thức về CPU, thành phần không thể thiếu trong các chip SoC, MCU, và là kiến thức tối quan trọng trong lĩnh vực vi mạch số |
| 2 | Thiết kế CPU đa nhân (multicore) | Thiết kế một CPU có 2 core vật lý trở lên. Khác với đề tài thiết kế 1 core, bạn tập trung phát triển 1 CPU hỗ trợ càng nhiều lệnh càng tốt, chạy càng nhanh càng tốt thì đề tài này bạn tập trung đến vấn đề tối ưu xử lý và phối hợp giữa các core. Kiến trúc mỗi core có thể lựa chọn đơn giản vì đây không phải mục tiêu chính. Ưu điểm, multicore là xu thế công nghệ hiện tại, đây cũng là đề tài mới ở Việt Nam. |
| 3 | Thiết kế bộ quản lý và truy xuất bộ nhớ Cache trong CPU | Việc xử lý nhanh hay chậm của CPU liên quan mật thiết đến thời gian truy xuất bộ nhớ chương trình và bộ nhớ dữ liệu. Để giảm thời gian này, các CPU hỗ trợ bộ nhớ đệm Cache. Việc quản lý truy xuất bộ nhớ này là một phần quan trọng trong hoạt động CPU. Đối với đề tài này, bạn không thiết kế CPU mà tập trung nghiên cứu và hiện thực có hiệu quả thành phần quản lý và truy xuất Cache. (https://en.wikipedia.org/wiki/CPU_cache) |
| 4 | Thiết kế CPU có kiến trúc superscalar | Trong khi Pipeline là kiến trúc giúp giảm số chu kỳ xử lý của một lệnh và hướng đến mục tiêu 1 lệnh/1 chu kỳ, đề tài này đã có nhiều bạn thực hiện thì kiến trúc superscalar giúp CPU xử lý hai hoặc nhiều lệnh song song nhau làm tăng hiệu suất đáng kể. (https://en.wikipedia.org/wiki/Superscalar_processor) |
| 5 | Thiết kế Java CPU | Một CPU có phần cứng hỗ trợ máy ảo Java giúp thực thi code Java nhanh hơn các CPU thông thường. (https://en.wikipedia.org/wiki/Java_processor) |
| 6 | Thiết kế hệ thống BUS đa tầng, phân chia truy cập theo khu vực | Trong một SoC, nếu chỉ có một BUS gắn nhiều master và slave thì tốc độ xử lý và hiệu suất hệ thống sẽ rất chậm. Nó giống như việc chỉ có một con đường duy nhất dẫn đến nhiều địa điểm khác nhau nên khi nhiều người cùng muốn đi thì tình trạng "kẹt xe" xảy ra. Trong đề tài này, vấn đề chính bạn cần giải quyết là xây dựng mô hình hệ thống BUS đa tầng để phân luồng truy cập cho các master đến các slave. Chú ý, thiết kế chi tiết, viết RTL code cho tuwngf BUS không phải mục tiêu của đề tài. Mục tiêu chính của đề tài này là bạn có một mô hình SoC với các master, slave có tốc độ xử lý, chức năng khác nhau và bận cần xây dựng (build) một hệ thống BUS kết nối chúng sao cho hiệu suất hoạt động của toàn hệ thống trong ứng dụng là tốt nhất. Cái khó là làm sao để chứng minh, đánh giá và so sánh hệ thống của bạn với hệ thống khác. |
| 7 | Thiết kế lõi xử lý tín hiệu số DSP | Khác với các lõi CPU thông thường, DSP là một loại vi xử lý chuyên dụng hỗ trợ các ứng dụng xử lý tín hiệu số, việc thiết kế lõi DSP yêu cầu 2 vấn đề là phải hỗ trợ tính toán số học và đáp ứng thời gian thực. Vì vậy, ngoài các lệnh cơ bản như một CPU thông thường, DSP còn hỗ trợ nhiều lệnh hỗ trợ tính toán số học như tính toán dấu chấm tĩnh (fixed-point), dấu chấm động (floating-point), MAC (Multiply-And-Accumulate), CONV (Convolution),... Tham khảo: http://liu.diva-portal.org/smash/get/diva2:281329/FULLTEXT02 |
| 8 | Thiết kế bus hệ thống WISHBONE | Đây là một chuẩn bus mở. Mục đích của nó là thúc đẩy việc tái sử dụng thiết kế bằng cách cố gắng giảm bớt các vấn đề tích hợp hệ thống trên chip. WISHBONE tạo ra một giao diện hợp lý, phổ biến giữa các lõi IP từ đó giúp giảm thời gian phát triển một sản phẩm SoC. THam khảo: https://opencores.org/howto/wishbone |
| 9 | Thiết kế cầu chuyển đổi AXI-to-WISHBONE | Thiết kế chuyển đổi giữa giao thức bus AXI (thuộc bộ giao thức AMBA) và giao thức bus WISHBONE. Điểm khó của đề tài này là làm thế nào chuyển đổi hiệu quả, ít ảnh hưởng đến hiệu suất hệ thống bus. |
| 10 | Thiết kế các cơ chế đảm bảo chức năng an toàn cho các transaction trong BUS hệ thống | Bus hệ thống như AXI, AHB, APB, WISHBONE, OCP, CoreConnect, ... có nhiệm vụ trung chuyển dữ liệu, thông tin giữa các thành phần trong hệ thống. Tuy nhiên, các giao thức BUS không quy định đầy đủ các cơ chế để phát hiện và xử lý tình huống các tình huống lỗi có thể xảy ra khi chip bị ảnh hưởng bởi nhiệt độ, nhiễu, ... Đối với các ứng dụng yêu cầu mức độ an toàn cao, hệ thống bus phải được thiết kế thêm các chức năng an toàn để phát hiện kịp thời các lỗi khi dữ liệu được vận chuyển trong hệ thống BUS. Từ đó, dữ liệu được truyền từ một master đến một slave thông qua hệ thống bus được đảm bảo chính xác. Nhiệm vụ đề tài là phân tích các lỗi có thể xảy trong hệ thống BUS, cơ đế để phát hiện các lỗi này, thiết kế các logic cho từng cơ chế và tích hợp vào trong một hệ thống bus. Chú ý, việc thêm cơ chế bảo vệ không làm thay đổi giao thức của chuẩn BUS. Tham khảo: các dòng chip được chứng nhận Functional Safety (http://www.ti.com/ww/en/functional_safety/safeti/SafeTI-26262.html) |
Tham khảo thêm:
1/ Download dễ dàng danh sách hơn 100 báo cáo đề tài, luận án về lĩnh vực thiết kế vi mạch, điện tử của sinh viên các nước:
https://www.electronicshub.org/vlsi-projects-for-engineering-students/
2/ Danh sách tên gợi ý các đề tài, bài tập lớn thực hiện với ngôn ngữ mô tả phần cứng trên FPGA:
http://www.siliconmentor.com/fpga-design-and-verilog-hdl-projects-list/
http://technofist.com/VLSI-Projects.html
3/ Download bài báo, đề tài, luận án đã được hoàn thành và công bố của khoa công nghệ và điện tử trường đại học Toronto (Chú ý, tập tin luận án định dạng ".ps" - PostScript, bạn cần download phần mềm chuyên dụng để xem hoặc chuyển đồi file này thành file .pdf):
http://www.eecg.toronto.edu/~pc/research/fullpublist/
Còn tiếp tục cập nhật ...
1/ Download dễ dàng danh sách hơn 100 báo cáo đề tài, luận án về lĩnh vực thiết kế vi mạch, điện tử của sinh viên các nước:
https://www.electronicshub.org/vlsi-projects-for-engineering-students/
2/ Danh sách tên gợi ý các đề tài, bài tập lớn thực hiện với ngôn ngữ mô tả phần cứng trên FPGA:
http://www.siliconmentor.com/fpga-design-and-verilog-hdl-projects-list/
http://technofist.com/VLSI-Projects.html
3/ Download bài báo, đề tài, luận án đã được hoàn thành và công bố của khoa công nghệ và điện tử trường đại học Toronto (Chú ý, tập tin luận án định dạng ".ps" - PostScript, bạn cần download phần mềm chuyên dụng để xem hoặc chuyển đồi file này thành file .pdf):
http://www.eecg.toronto.edu/~pc/research/fullpublist/
Còn tiếp tục cập nhật ...
Nếu bạn có gợi ý hay góp ý, vui lòng comment dưới bài viết hoặc email về nguyenquan.icd@gmail.com